


The BD (Businesse Deletate) in an interface that provides a lot of crud and business methods. Once a user has available the BD interface in his class, he has just to call his methods to perform very advanced operations. The methods are about looking for specific objects, or collections of objects that satisfy some condition passed trough input parameters, or performing complex queries, or persistence simple o strongly structured objects, or dealing with complex object manipulation as tree merging, or transformation of tree structure in plane structure and so on. All this putting just the right method in your class. Forget queries, forget connexion, forget transaction (well, at least if what you need is in Mandragora yet). Just give mandragora the object you want to store (complex as you want), and don't worry more. Just tell mandragora which class is instance of the object you need and the values of his keys. You will be served.
In this section we will present the methods of the interface BD using the following example:
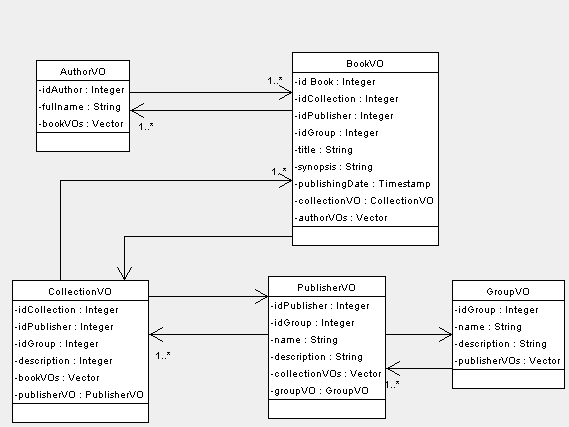
Mandragora hides the implementation details to the user, that in theory shouldn't know which kind of persistence system is used, in which way value objects are related with media store, so the user should just deals with value objects, and their relationships. He should just know the class diagram of the value objects as the one in the figure above. All is back the interface BD (that is the unique user access point) shouldn't be a user problem. Changing the configuration in Mandragora.properties the user chooses his implemenation, and then he can forget. In the practice at the moment the only two implementation existing in Mandragora are based on a DAO that use the framework Ojb as persistence engine . So in our example we suppose that the class diagram in the figure above is mapped with with a database, so each class with a table, and each field with a column.
In this guide we will refer to a client as to the class that uses Mandragora. To have available a BD implementation in your client, you have just to do:
| BD bd = ServiceLocator.getInstance().getManagerBD("BDFactoryDefaultClass","DefaultBDFactory.BDClass"); |
The class it.aco.mandragora.common.ServiceLocator is a singleton class. The method getManagerBD has two input String parameter; the first one is out of the goals of this section and will be discussed lookup and mapping section. The second parameter specifies the real class that implements the interface it.aco.mandragora.bd.BD. The value of this parameter has to be mapped in the file Mandragora.properties. Mandragora, at the moment has just two implementation of the interface BD:
The differences between this two implementations will be discussed in the section relative to ejb support. In the Mandragora.properties DefaultBDFactory.BDClass is mapped to it.aco.mandragora.bd.impl.pojo.PojoManagerBD. This means that it has an entry:
| DefaultBDFactory.BDClass=it.aco.mandragora.bd.impl.pojo.PojoManagerBD |
If you would use the implementation it.aco.mandragora.bd.impl.SLSB.SLSBManagerBD, just change the mapping, or if you prefer, add such an entry to Mandragora.properties
| statelessEjbBDClass=it.aco.mandragora.bd.impl.SLSB.SLSBManagerBD |
and get the BD in the following way
| BD bd = ServiceLocator.getInstance().getManagerBD("BDFactoryDefaultClass","statelessEjbBDClass"); |
Of course you can write your own implementation and map it in Mandragora.properties. Nothing forbids you to use different implementations in different point of your application, or of the same client.
Here we will show and explain methods to create, read, update and delete simple, complex and structured value objects.
Reader methods are methods that just read in the media store without doing any operation of insert, update or delete. So they leave the media store unchanged. This methods just perform select queries. We classify them in 3.1.1 - finder methods, 3.1.2 - retriever methods and 3.1.3 - report methods.
Finder methods return value objects mapped with database tables, or collection of such value objects, each of which could be the root of a more complex structure. So these methods return business objects. For example they can return an instance of the class BookVO, where each attribute is populated with the mapped field values of some row of the corresponding table, or they can return a collection of instances of BookVO. Value objects returned can be strongly structured. For example each instance of BookVO returned can have the attribute collectionVO populated with the row of the table mapped to the class CollectionVO related with the instance of BookVO returned, and the attribute publisherVO of the collectionVO populated in the same way. If attributes of relationship are populated or not depends by the mapping configuration. Using Ojb implementation for the DAO, it will depend by the value of autoretrieve in the repository.xml
These methods return the instance of a class specified by an input parameter, whose fields are filled with the columns values of the record of the table mapped with the specified input class, and which key values of the record are specified by input parameters too.
Mandragora has three methods findByPrimaryKey:
If in our example the class BookVO is mapped to a table called book, and the primary keys of book are idBook, idCollection, idPublisher,idGroup, if you put the following code:
| try { BD bd = ServiceLocator.getInstance().getManagerBD("BDFactoryDefaultClass","DefaultBDFactory.BDClass"); BookVO bookVO= (BookVO)bd.findByPrimaryKey(BookVO.class,new Object[]{new Integer(22),new Integer(43),new Integer(11),new Integer(8)}) } catch (ApplicationException e) { //manage the exception } |
bookVO will be an instance of BookVO, and his fields values are the correspondent columns values of the record of the table book which keys values are 22,43,11,8.
The order in which values specified in the array Object[] pkValues are compared with the primary key columns depends on the BD implementation detail. For example if the implentation (as is the case) use a DAO with Ojb, the order is the one specified in the repository.xml
If you want specify directly the order you can use for example:
| BookVO bookVO= (BookVO)bd.findByPrimaryKey(BookVO.class, new String[]{"idBook", "idCollection", "idPublisher", "idGroup"}, new Object[]new Integer(22),new Integer(43),new Integer(11),new Integer(8)) |
In this way you are explicitly specifying which fields are primary key, and for each one which is his value.
In the case the value object/column, has just one primary key you can use the third method. Such a case is the AuthorVO which only primary key is idAuthor:
| AuthorVO authorVO= (AuthorVO)bd.findByPrimaryKey(AuthorVO.class, new Integer(9)); |
authorVO will contain the data of author number 9
If an element with the introduced keys does not exist in the media store a null will be returned.
A template is an instance of a value object class with some of his field populated. Methods findByTemplate are used to look for all objects in the media store associated with the class of the template, and with the same value for the populated fields.
So if the media store is a RDBMS, and the class of the template is associated to a table, and fields of class are associated to table's columns, these methods return all records (creating for each one an instance of the class, and filling his fields with the values of the relative columns of the record), return all records that match with the template. We say that a record match with a template, if all not null fields of the template have the same value of the relative columns of the record.
Mandragora has three methods findByTemplate:
The three methods have the same behavior, with the only difference that the first one return a collection, and the second one return just one object. If we use the second one, findObjectByTemplate(Object templateVO), if more than one record match with the template, an exception is thrown.
For example if we have a class CarVO with many fields, two of which are color and engine, if we do :
| try { BD bd = ServiceLocator.getInstance().getManagerBD("BDFactoryDefaultClass","DefaultBDFactory.BDClass"); car = new CarVO(); car.setColor("red"); car.setEngine("mercedes"); Collection carVOs = bd.findCollectionByTemplate(car); // carVOs hold all cars whose color is red an whose engine is mercede } catch (ApplicationException e) { //manage the exception } |
Will be returned all cars whose color is red an whose engine is mercedes.
The third method is like the first one, but an ordering field can be specified, and a parameter specifying if ordering must be ascendant (true value) or descendant (false value) to. Suppose our CarVO has a field named model. If we want our list be ascendantly ordered by the field model we just have to use the third method in the following way:
| Collection carVOs = bd.findOrderedCollectionByTemplate(car, "model", true); |
If no car exists with the specified conditions an empty collection will be returned.
There is now only one method to find collection by null fields:
This method looks for all instances of the class specified by the input parameter, which fields specified by the input parameter are null. The class must be mapped to some table of the underlying media store, and the array of strings must specify fields of the class, and these fields must be mapped to columns of the associated table. The method creates and returns a collection of instances of this class, one instance for each record in the related table which columns mapped with the input fields have null values In the example of author, book an publisher, if we want to look for all publisher which description and name are both null we can do:
| Collection publisherVOs = bd.findCollectionByNullFields(PublisherVO.class, new String[]"description","name"); |
Strings could be a path to the fields of other directly or indirectly related classes too. For example if we want to look for all authors that are related with at least one publisher with a null description we can do:
| Collection authorVOs = bd.findCollectionByNullFields(AuthorVO.class, new String[]"bookVOs.collectionVO.publisherVO.description"); |
Note that being a an author related to more books, if just one book of the author belong to a collection published by a publisher with a null description, the author will be added to the collection to return. If no instance can be found an empty collection will be returned.
Before reading have a look to LogicCondition
Methods that find collections by logic conditions are used to look for all records of a table, in the media store associated with the class specified in input, that match with a specified condition.
The methods that use logic conditions are:
The best way to illustrate how it works is to show some example.
Suppose you have a value object class called EmployeeVO, and you want all employees with age<35 and a salary >=40000. You have just to do write the code
| try { BD bd = ServiceLocator.getInstance().getManagerBD("BDFactoryDefaultClass","DefaultBDFactory.BDClass"); Collection employeeVOs = bd.findCollectionByLogicCondition(EmployeeVO.class,new LogicSqlCondition("age","<=",new Integer(35),"AND", new LogicSqlCondition("salary",">=", new Integer(40000)))); // The collection employeeVOs will hold all instances of EmployeeVO.class where age <=35 and salary >= 40000 } catch (ApplicationException e) { //manage the exception } |
The collection employeeVOs will hold all instances of EmployeeVO.class where age <=35 and salary >= 40000
Consider now the class diagram described in the introduction; suppose you want to get all authors who wrote at list one book with the publisher named "Mondatori". The logic condition will be:
| LogicSqlCondition authorsOfMondatoriLogicSqlCondition = new LogicSqlCondition("bookVOs.collectionVO.publisherVO.name","==", "Mondatori"); |
Now to get the authors we want just do:
| Collection authorVOs = bd.findCollectionByLogicCondition(AuthorVO.class,authorsOfMondatoriLogicSqlCondition); |
An other example: suppose you want now to get all publisher which have between his authors "Monica Gutierrez Sancho" or "Gabriel Garcia Marquez" you have to do:
| Collection publisherVOs = bd.findCollectionByLogicCondition(PublisherVO.class,new LogicSqlCondition("collectionVOs.bookVOs.authorVOs.fullname","==","Monica Gutierrez Sancho","or", new LogicSqlCondition("collectionVOs.bookVOs.authorVOs.fullname","==", "Gabriel Garcia Marquez"))); |
If you want to get all publisher of the group "Random House Mondatori" you have to do :
| Collection publisherVOs = bd.findCollectionByLogicCondition(PublisherVO.class,new LogicSqlCondition("groupVO.name","==","Random House Mondatori")); |
There are many ways to build a logic condition. The one exposed here needs to be specified the following input parameters:
These methods are recursive, so you can make a condition long a complex as you want. For each added condition a parenthesis is opened, so the resulting logic condition will be:
| (condition1 AND/OR (condition2 AND/OR (condition3 AND/OR (... AND/OR (conditionN)...))) |
This method returns all records of a table, in the media store associated with the class specified in input, where the field specified by the input parameter property, has as value one of the values specified by the collection values.
For example, suppose you want all car which engines are mercedes or ford; you just need to create a collection holding the values "mercedes" and "ford" and just do:
| Collection fordMercedesCarVOs = bd.findCollectionByOrValues(CarVO.class,"engine", values); |
The method is :
This method returns all records of a table, in the media store associated with the class specified by the input parameter clazz which has each field in the array properties not equals to the correspondent value in the array values. In other words must be verified the condition: (properties[i]!=values[i]). If arrays are empty all instances will be returned.
The method is :
This method returns all records of a table in the media store associated with the class specified by the input parameter clazz, as a collection of instances of the same class clazz, which satisfy the condition :
| properties[i] operators[i] values[i] for each i |
For example, referring to the example in the introduction, suppose you want all books of the publisher with id 10, but not of the collection with id 5, and with published before of 20/01/2004. You should create three arrays, one for the properties, or fields which has to be applied the condition, one for the operators, and one for values.
| SimpleDateFormat sdf = new SimpleDateFormat("dd/MM/yyyy"); String[] properties = new String[]{"idPublisher","idCollection","publishingDate"}; String[] operators = new String[]{"==","<>","<"}; Object[] values = new Object[]{new Integer(10), new Integer(5), new Timestamp(sdf.parse("20/01/2004").getTime())}; try { BD bd = ServiceLocator.getInstance().getManagerBD("BDFactoryDefaultClass","DefaultBDFactory.BDClass"); Collection bookVOs = bd.findCollectionByAndFieldsOperatorValues(BookVO.class, properties, operators, values); // bookVOs hold all books that satisfy the 3 conditions } catch (ApplicationException e) { //manage the exception } |
Operators accepted are : ==,=,<=,>=,<,>,!=,<>
If arrays are empty all instances are returned.
The method is :
This method returns all records of a table in the media store associated with the class specified by the input parameter clazz, as a collection of instances of the same class clazz, which satisfy AND-OR condition. The AND-OR condition is the AND of properties[j] operators[j] values[j][i] for each i, in OR for each j. So if we have an M x N matrix (M row and N column) of values, the arrays properties and operators must have both N elements.
So the condition will be:
| ((properties[0] operators[0] values[0][0]) AND ... AND (properties[N-1] operators[N-1] values[0][N-1])) OR ((properties[0] operators[0] values[1][0]) AND ... AND (properties[N-1] operators[N-1] values[1][N-1])) OR ((properties[0] operators[0] values[M-1][0]) AND ... AND (properties[N-1] operators[N-1] values[M-1][N-1])) |
As example suppose values is a 2X2 matrix where values[0][0]=0,values[0][1]=1,values[1][0]=10,values[1][1]=11
suppose properties="property0", "property1" and suppose operators="<",">"
the condition will be (property0<0 AND property1 >1) OR (property0<10 AND property1>11)
Here is an other example relative to the diagram in the introduction: suppose you want the list of books that satisfy the condition of being published before the 20/01/2005 by the publisher with id 45 in the collections with id greater than 22, or being published before the 15/02/2003 by the publisher with id 40, in collections with id greater than 18. The condition is :
| ((publishingDate < 20/01/2005) AND (idPublisher == 45) AND (idCollection > 22)) OR ((publishingDate < 15/02/2003) AND (idPublisher == 40) AND (idCollection > 18)) |
So in java code it will be:
| SimpleDateFormat sdf = new SimpleDateFormat("dd/MM/yyyy"); String[] properties = new String[]{"publishingDate","idPublisher","idCollection"}; String[] operators = new String[]{"<","==",">"}; Object[][] values = new Object[2][3]; values[0][0] = new Timestamp(sdf.parse("20/01/2005").getTime()); values[0][1] = new Integer(45); values[0][2] = new Integer(22); values[1][0] = new Timestamp(sdf.parse("15/02/2003").getTime()); values[1][1] = new Integer(40); values[1][2] = new Integer(18); try { BD bd = ServiceLocator.getInstance().getManagerBD("BDFactoryDefaultClass","DefaultBDFactory.BDClass"); Collection bookVOs = bd.findCollectionByArrayOfFieldsOperatorsMatrixAndOrValues(BookVO.class, properties, operators, values); // bookVOs hold all books that satisfy condition } catch (ApplicationException e) { //manage the exception } |
We can resume telling that the elements of each row are in AND between them, and the all the row are in OR between them. Note the condition expressed by each element of the same column has involved the same element of the array properties and the same element of the array operators (in other word the same property and the same operator). For more complex conditions findByLogicCondition can be used.
This method is very useful to find a list of object, that have composite primary key, of which we have primary keys. For example consider that the key of book is :(idBook, idCollection, idPublisher, idGroup). I we want to get the books that have one of the following primary keys: (2,12,34,45) or (13,56,23,11) or (22,43,12,55), the java code will be:
| String[] properties = new String[]{"idBook", "idCollection", "idPublisher", "idGroup"}; String[] operators = new String[]{"==", "==", "==", "=="}; Object[][] values = new Object[2][3]{new Integer(10), new Integer(5), new Timestamp(sdf.parse("20/01/2004").getTime())}; values[0][0] = new Integer(2); values[0][1] = new Integer(12); values[0][2] = new Integer(34); values[0][3] = new Integer(45); values[1][0] = new Integer(13); values[1][1] = new Integer(56); values[1][2] = new Integer(23); values[1][3] = new Integer(11); values[2][0] = new Integer(22); values[2][1] = new Integer(43); values[2][2] = new Integer(12); values[2][3] = new Integer(55); try { BD bd = ServiceLocator.getInstance().getManagerBD("BDFactoryDefaultClass","DefaultBDFactory.BDClass"); Collection bookVOs = bd.findCollectionByArrayOfFieldsOperatorsMatrixAndOrValues(BookVO.class, properties, operators, values); // bookVOs hold all books that satisfy condition } catch (ApplicationException e) { //manage the exception } |
Note that the collection bookVOs can hold less than 3 elements, as some of the primary keys could no exist
Operators accepted are : ==,=,<=,>=,<,>,!=,<>
Note!! Arrays must be not Null!!
The method is :
This method returns all records of a table in the media store associated with the class specified by the input parameter clazz, as a collection of instances of the same class clazz, that have the field specified by the input parameter property, that has his value equal to one of ones in the collection values
For example suppose you want all the books of one of the author Monica Gutierrez Sancho, Gabriel Garcia Marquez, Paul Auster.
The java code will be:
| Vector values = new Vector; values.add("Monica Gutierrez Sancho"); values.add("Gabriel Garcia Marquez"); values.add("Paul Auster"); try { BD bd = ServiceLocator.getInstance().getManagerBD("BDFactoryDefaultClass","DefaultBDFactory.BDClass"); Collection bookVOs = bd.findCollectionByFieldInCollection(BookVO.class, "authorVOs.fullname", values); // bookVOs hold all books of the three authors } catch (ApplicationException e) { //manage the exception } |
If the collection values is null or empty a null will be returned.
The method is :
This method returns all records of a table in the media store associated with the class specified by the input parameter clazz, as a collection of instances of the same class clazz, that holds the value specified in input in one of fields in the array properties Matching instances must satisfy:
| instance.properties[i] Like %value% for at list one i. |
For example suppose you want all the books which title or synopsis hold the sentence "I will tell you the secret". You should do:
| String[] properties = new String[]"title", "synopsis"; try { BD bd = ServiceLocator.getInstance().getManagerBD("BDFactoryDefaultClass","DefaultBDFactory.BDClass"); Collection bookVOs = bd.searchValueInFields(BookVO.class, properties, "I will tell you the secret"); // bookVOs hold all books of the condition } catch (ApplicationException e) { //manage the exception } |
This kind of methods populate attributes of a class that references an other class or collection, retrieving data from the underlying media store. So if you have an instance of some class mapped to a table, and you have an attribute that refers to an instance or collection of instances of a second class mapped to some table too, with these methods you can populate such attributes with the rows of the table related to the class referred by the first class. So if you have an instance of BookVO, you can retrieve from the database the correspondent collection of instances of the class AuthorVO and use it to populate the attribute authorVOs of the instance of BookVO. Value objects retrieved are business objects too, so they can be strongly structured in the same way of finder methods.
The method is :
The object pInstance must be of a class that have the value of pAttributeName as name of one of his property; this property must refer to an other object or collection of objects. The referenced object or collection will be loaded from the underlying media store. For example suppose you have an object called bookVO of the class BookVO. One of his field is authorVOs, that is a collection. If you want the authors of the book be loaded from the media store, each one in an instance of AuthorVO, and all the instance put in a the collection, bookVO.authorVOs you must do:
| try { BD bd = ServiceLocator.getInstance().getManagerBD("BDFactoryDefaultClass","DefaultBDFactory.BDClass"); bd.retrieveReference(bookVO, "authorVOs"); // bookVO.authorVOs hold all authors of the book represented by bookVO } catch (ApplicationException e) { //manage the exception } |
As an other example, if you have an object publisherVO, instance of PublisherVO, and you want populate his field groupVO, representing the group that hold the publisher represented by publisherVO you must do:
| try { BD bd = ServiceLocator.getInstance().getManagerBD("BDFactoryDefaultClass","DefaultBDFactory.BDClass"); bd.retrieveReference(publisherVO, "groupVO"); // publisherVO.groupVO hold the group of the publisher } catch (ApplicationException e) { //manage the exception } |
This method overwrite the existing value of the referenced object or collection that are being retrieved.
The method is :
With this all objects or collections referenced by pInstance will be loaded from the underlying media store. For example you can see in the figure in the introduction that an instance of the class PublisherVO reference the collection collectionVOs and the object groupVO. If you want to retrieve both of them from the underlying media store you have to do:
| try { BD bd = ServiceLocator.getInstance().getManagerBD("BDFactoryDefaultClass","DefaultBDFactory.BDClass"); bd.retrieveAllReferences(publisherVO); // publisherVO.collectionVOs hold all collections of the publisher and publisherVO.groupVO hold his group } catch (ApplicationException e) { //manage the exception } |
This method overwrite the existing value of the referenced object or collection that are being retrieved.
The method is :
This method acts as retrieveReference with the difference that the operation is performed on all elements of collection. For example suppose you have a collection of instances of the class BookVO; we call it bookVOs. If you want to retrieve from the database all the authors of each book in the collection bookVOs, and for each bookVO create the collection of his author and load it in the the collection bookVO.authorVOs you have just to do:
| try { BD bd = ServiceLocator.getInstance().getManagerBD("BDFactoryDefaultClass","DefaultBDFactory.BDClass"); bd.retrieveReferenceInCollection(bookVOs, "authorVOs"); // for each bookVO of the collection bookVOs, bookVO.authorVOs hold all authors of the book represented by bookVO } catch (ApplicationException e) { //manage the exception } |
As an other example, if you have a collection of instances of the class PublisherVO; we call it publisherVOs. If you want to retrieve from the database the group of each publisher in the collection publisherVOs, and for each one create an instance of GroupVO and load it in publisherVO.groupVO, you have just to do
| try { BD bd = ServiceLocator.getInstance().getManagerBD("BDFactoryDefaultClass","DefaultBDFactory.BDClass"); bd.retrieveReferenceInCollection(publisherVOs, "groupVO"); // for each publisherVO in ther collection publisherVOs, publisherVO.groupVO hold the group of the publisher } catch (ApplicationException e) { //manage the exception } |
This method overwrite the existing value of the referenced objects or collections that are being retrieved.
The method is :
This method acts as retrieveAllReferences with the difference that the operation is performed on all elements of collection. For example suppose you have a collection of instances of PublisherVO; we call it publisherVOs. As you can see in the figure in the introduction an instance of the class PublisherVO reference the collection collectionVOs and the object groupVO. If you want to retrieve both of them from the underlying media store for each publisher in the collection publisherVOs you have to do:
| try { BD bd = ServiceLocator.getInstance().getManagerBD("BDFactoryDefaultClass","DefaultBDFactory.BDClass"); bd.retrieveAllReferencesInCollection(publisherVOs); //for each publisherVO in ther collection publisherVOs, publisherVO.collectionVOs hold all collections of the publisher and publisherVO.groupVO hold his group } catch (ApplicationException e) { //manage the exception } |
This method overwrite the existing value of the referenced objects or collections that are being retrieved.
The method is :
This method acts as retrieveAllReferences with the difference that retrieves not null references. For example you can see in the figure in the introduction that an instance of the class PublisherVO reference the collection collectionVOs and the object groupVO. If you have the object publisherVO and you apply the code:
| try { BD bd = ServiceLocator.getInstance().getManagerBD("BDFactoryDefaultClass","DefaultBDFactory.BDClass"); bd.retrieveAllNullReferences(publisherVO); } catch (ApplicationException e) { //manage the exception } |
'publisherVO.groupVO' will be retrieved from the database just if 'publisherVO.groupVO' is null. Analogously for 'publisherVOs.collectionVOs'.
The method is :
This method retrieves references in objects or collections found following the path specified in the input starting from valueobjectOrCollection. Suppose you have an author who wrote many books each of which belongs to a collection of a publishing house hold by a group as you can see in the figure of the introduction. Suppose that your author is represented by the object 'authorVO', and you want that 'authorVO.bookVOs' be filled with instances of the class BookVO representing his books, and for each element 'bookVO', 'bookVO.collectionVO' be retrieved too, and so for 'bookVO.collectionVO.publisherVO' and 'bookVO.collectionVO.publisherVO.groupVO'. The java code is:
| try { BD bd = ServiceLocator.getInstance().getManagerBD("BDFactoryDefaultClass","DefaultBDFactory.BDClass"); bd.retrievePathReference(authorVO,"bookVOs.collectionVO.publisherVO.groupVO"); } catch (ApplicationException e) { //manage the exception } |
So all books of the author will be retrieved, and for each book his collection, publisher and group will be retrieved, and all will be organized in the java structure as the figure in the introduction. The input parameter valueobjectOrCollection, as his name says, can be a value object or a collection of value objects. If it is a collection the same rule will be applied to all his elements. For example if we have a collection of author, that we call 'authorVOs', instead of a single author, and and for each author we would all his books, each one with his collection, publisher and group we should do:
| try { BD bd = ServiceLocator.getInstance().getManagerBD("BDFactoryDefaultClass","DefaultBDFactory.BDClass"); bd.retrievePathReference(authorVOs,"bookVOs.collectionVO.publisherVO.groupVO"); } catch (ApplicationException e) { //manage the exception } |
This method automatically detects if the first input parameter is a single value object or a collection, and recursively for each attribute retrieved it detects if they are single value object or a collection. To make it work all class involved in the retrieving must extend the Mandragora class 'it.aco.mandragora.vo.ValueObject'
Report queries are used to retrieve row data, not 'real' business objects. They do not return value objects mapped with database tables, or collection of such value objects, each of which could be the root of a more complex structure following the the mapping confoguration, as for finder methods or retriever methods. A row data is an array of Object. With these queries you can define what attributes of an object you want to have in the row. The attribute names may also contain path expressions like 'collectionVO.publisherVO.groupVO'. So each row of a report is an array of objects, and these objects are attribuetes of one or more realted value objects.
The method is :
Before reading have a look to LogicCondition
The parameters clazz and attributes, specify which attributes of which classes (so which table as each class must be mapped to a table) must belong to the report. The parameter clazz is the starting class, and each attribute of the array attributes specify the attribute of clazz if it is not a path expression, while if it is, it is an attribute of the class individuated by the path expression starting from the same class clazz. For example, following the diagram in the introduction, if you put as starting class BookVO, and one of the attribute is "collectionVO.publiherVO.name" this attribute will be the field 'name' of the class PubliherVO. If an attribute is just "title" it will be the field 'title' of the same class BookVO. An attribute can be a function to, for example "sum(somefield)" or "count(somefield)" and so on.. In this case can be specified which attributes will belong to the groupBy clause. The parameter logicCondition specify which rows have to be retrieved This method returns an iterator over a collection of Object[n] of the attributes values, where n, of course is the length of the array attributes Let's see an example: Suppose you want all the books one of the authors of which have full name "Gabriel Garcia Marquez", and for each one you want his title, the description of his collection, and the name of the publisher; The java code will be:
| try { LogicSqlCondition logicSqlCondition = new LogicSqlCondition("authorVOs.fullname","==", "Gabriel Garcia Marquez"); String[] attributes = new String[]"title", "collectionVO.description", "collectionVO.publisherVO.description" ; BD bd = ServiceLocator.getInstance().getManagerBD("BDFactoryDefaultClass","DefaultBDFactory.BDClass"); Iterator iterator = bd.getReportQueryIterator(BookVO.class, logicSqlCondition, "bookVOs.collectionVO.publisherVO.groupVO", null); // iterator is over a collection of Object[3], where each element of the collection is a row of the report. \// for each element element[0] is the title, element[1] is the description of the collection, element[2] is the description of the publisher } catch (ApplicationException e) { //manage the exception } |
The method is :
Inserts the object insertVO in the underlying datastore. The operation is atomic. Connection management and transaction management are fully delegated. User must no care at all!!. This method returns the same inserted object. For example if you want to insert a new book. You have to do:
| BookVO bookVO = new BookVO(); bookVO.setIdBook(new Integer(50)); bookVO.setIdCollection(new Integer(46)); bookVO.setIdPublisher(new Integer(12)); bookVO.setIdGroup(new Integer(2)); bookVO.setTitle("Si vuelves te contar� el secreto"); try { BD bd = ServiceLocator.getInstance().getManagerBD("BDFactoryDefaultClass","DefaultBDFactory.BDClass"); bookVO = bd.insert(bookVO); // bookVO hold the same inserted object } catch (ApplicationException e) { //manage the exception } |
In this simple example the referenced objects are null. With the same line 'bd.insert(bookVO);' you can insert a structured object just populating the attributes of bookVO related to the referenced objects, in this case the attributes collectionVO and authorVOs. For example suppose that the book you want to insert has just one author, and that it is a new one, so it must be inserted too int the table of authors; suppose too that the collection 46 is already existing; the code should be;
| BookVO bookVO = new BookVO(); bookVO.setIdBook(new Integer(50)); bookVO.setIdCollection(new Integer(46)); bookVO.setIdPublisher(new Integer(12)); bookVO.setIdGroup(new Integer(2)); bookVO.setTitle("Si vuelves te contar� el secreto"); AuthorVO authorVO = new AuthorVO(); authorVO.setIdAuthor(new Integer(123)); authorVO.setFullName("Monica Gutierrez Sancho"); Vector authorVOs = new Vector(); authorVOs.add(authorVO); authorVO.setAuthorVOs(authorVOs); try { BD bd = ServiceLocator.getInstance().getManagerBD("BDFactoryDefaultClass","DefaultBDFactory.BDClass"); bd.retrieve(bookVO,"collectionVO"); bookVO = bd.insert(bookVO); // bookVO hold the same inserted object } catch (ApplicationException e) { //manage the exception } |
The behavior of the method insert on the tables mapped with related classes AuthorVO and CollectionVO, (through the attributes authorVOs and collectionVO) depends by the mapping configuration. If you are using the defualt DAO based on PersistenceBroker of Ojb, have a look at the mapping configuration of ojb. Depending by this mapping it could be that all elements of the collection authorVOs be inserted, or if some of that yet existing on on the database, be updated on the database. Note that being the relationship between BookVO and AuthorVO M:N, in both cases (an author be inserted or updated) will be inserted a row in the corresponding table holding the M:N relationship. Analogously for the attribute collectionVO, as in other cases the value object collectionVO could be modified between the retrieve and insert. Setting the mapping properly, in our example, with insertVO will be inserted the book, the author, and updated the collection. All of that just doing 'insert(bookVO)', and without worrying about the connection and transaction management. If you are using Ojb, remember, that for 1:1 mapping if the referenced object is leaved null, the column of the foreign key will be nulled, even if the field of the value object mapped to the column is not null. Consider again the value object bookVO and his attribute collectionVO. Let's say that the class BookVO is mapped to the table BOOK, and the class CollectionVO mapped to the table COLLECTION. BOOK has a column named IDCOLLECTION that is foreign key to COLLECTION, and is mapped to the field idCollection. If bookVO.collectionVO is null, when you insert the bookVO, the column IDCOLLECTION will be null independently of the vale of the attribute idCollection.
Let's see an other example. We want to insert a new publisher whose name is Caballo de Troya, with idPublisher 14, and that must be hold by the group Random House Mondatori, that doesn't exist in the database. So the group must be inserted before to insert the publisher. If you create properly the value object publisherVO, doing 'insert(publisherVO)' all is done automatically:
| PublisherVO publisherVO = new PublisherVO(); publisherVO.setIdPublisher(new Integer(14)); publisherVO.setIdGroup(new Integer(3)); publisherVO.setName("Caballo de Troya"); publisherVO.setDescription("Publisher to discover new talents"); GroupVO groupVO = new GroupVO(); groupVO.setIdGroup(new Integer(3)); groupVO.setName("Random House Mondatori"); publisherVO.setGroupVO(groupVO); try { BD bd = ServiceLocator.getInstance().getManagerBD("BDFactoryDefaultClass","DefaultBDFactory.BDClass"); publisherVO = bd.insert(publisherVO); // publisherVO hold the same inserted object } catch (ApplicationException e) { //manage the exception } |
If the mapping configuration is properly set both publisher and group will be inserted in the correct order in an atomic transaction.
If now you want to insert a new publisher, belonging to the same group, and at the same time you want to modify the attribute description of the group.
| PublisherVO publisherVO = new PublisherVO(); publisherVO.setIdPublisher(new Integer(15)); publisherVO.setIdGroup(new Integer(3)); // Random House Mondatori publisherVO.setName("Grijalbo"); publisherVO.setDescription("some description"); try { BD bd = ServiceLocator.getInstance().getManagerBD("BDFactoryDefaultClass","DefaultBDFactory.BDClass"); bd.retrieve(publisherVO,"groupVO"); publisherVO.getGroupVO.setDescription("description of Random House Mondatori") publisherVO = bd.insert(publisherVO); // publisherVO hold the same inserted object } catch (ApplicationException e) { //manage the exception } |
In the above example, if the configuration mapping is properly set, will be inserted the publisher and updated the group.
Now we want to insert a new group, with his publishers each one with his collections each one with his books each one with his authors. As you can see in the diagram, as each publisher belongs to just one group, and each collection belongs to just on publisher, and each book belongs to just one collection, surly publishers, collections and books we want to insert don't exist in the database. But as the relationship between authors and books is M:N authors we want to insert can exist or not in the database.
| GroupVO groupVO = new GroupVO(); groupVO.setIdGroup(new Integer(30)); groupVO.setName("name of the group"); groupVO.setDescription("description of the group"); / PublisherVO publisher1VO = new PublisherVO(); // publisher1 of the group 30 publisher1VO.setIdPublisher(new Integer(1)); publisher1VO.setIdGroup(new Integer(30)); publisher1VO.setName(" name"); publisher1VO.setDescription("publisher 1 of the group 30"); CollectionVO collection1VO = new CollectionVO(); collection1VO.setIdCollection(new Integer(1));collection1VO.setIdPublisher(new Integer(1)); collection1VO.setIdGroup(new Integer(30)); collection1VO.setDescription("collection 1 of the publisher 1 of the group 30"); BookVO book1VO = new BookVO(); // book 1 of the collection 1 of the publisher 1 of the group 30 book1VO.setIdBook(new Integer(1)); book1VO.setIdCollection(new Integer(1)); book1VO.setIdPublisher(new Integer(1)); book1VO.setIdGroup(new Integer(30)); Vector authorVOs = new Vector(); // authors of the book 1 of the collection 1 of the publisher 1 of the group 30 AuthorVO authorVO = new AuthorVO(); authorVO.setIdAuthor(new Integer(101));authorVO.setFullname("some name"); authorVOs.add(authorVO); authorVO = new AuthorVO();authorVO.setIdAuthor(new Integer(102)); authorVO.setFullname("some other name");authorVOs.add(authorVO); book1VO.setAuthorVOs(authorVOs); BookVO book2VO = new BookVO();// book 2 of the collection 1 of the publisher 1 of the group 30 book2VO.setIdBook(new Integer(2)); book2VO.setIdCollection(new Integer(1)); book2VO.setIdPublisher(new Integer(1)); book2VO.setIdGroup(new Integer(30)); authorVOs = new Vector(); //authors of the book 2 of the collection 1 of the publisher 1 of the group 30 authorVO = new AuthorVO();authorVO.setIdAuthor(new Integer(103));authorVO.setFullname("some name"); authorVOs.add(authorVO); authorVO = new AuthorVO();authorVO.setIdAuthor(new Integer(104)); authorVO.setFullname("some other name");authorVOs.add(authorVO); book2VO.setAuthorVOs(authorVOs); Collection bookVOs = new Vector(); // books of the collection 1 of the the publisher 1 of the group 30 bookVOs.add(book1VO);bookVOs.add(book2VO); collection1VO.setBookVOs(bookVOs); CollectionVO collection2VO = new CollectionVO(); collection2VO.setIdCollection(new Integer(2));collection2VO.setIdPublisher(new Integer(1)); collection2VO.setIdGroup(new Integer(30)); collection2VO.setDescription("collection 2 of the publisher 1 of the group 30"); book1VO = new BookVO(); //book 1 of the collection 2 of the publisher 1 of the group 30 book1VO.setIdBook(new Integer(1)); book1VO.setIdCollection(new Integer(2)); book1VO.setIdPublisher(new Integer(1)); book1VO.setIdGroup(new Integer(30)); authorVOs = new Vector(); // authors of the book 1 of the collection 2 of the publisher 1 of the group 30 AuthorVO authorVO = new AuthorVO(); authorVO.setIdAuthor(new Integer(105));authorVO.setFullname("some name"); authorVOs.add(authorVO); authorVO = new AuthorVO();authorVO.setIdAuthor(new Integer(106)); authorVO.setFullname("some other name");authorVOs.add(authorVO); book1VO.setAuthorVOs(authorVOs); BookVO book2VO = new BookVO(); //book 2 of the collection 2 of the publisher 1 of the group 30 book2VO.setIdBook(new Integer(2)); book2VO.setIdCollection(new Integer(2)); book2VO.setIdPublisher(new Integer(1)); book2VO.setIdGroup(new Integer(30)); authorVOs = new Vector(); //authors of the book 2 of the collection 2 of the publisher 1 of the group 30 authorVO = new AuthorVO();authorVO.setIdAuthor(new Integer(107));authorVO.setFullname("some name"); authorVOs.add(authorVO); authorVO = new AuthorVO();authorVO.setIdAuthor(new Integer(108)); authorVO.setFullname("some other name");authorVOs.add(authorVO); book2VO.setAuthorVOs(authorVOs); bookVOs = new Vector(); // books of the collection 2 of the the publisher 1 of the group 30 bookVOs.add(book1VO);bookVOs.add(book2VO); collection2VO.setBookVOs(bookVOs); Vector collectionVOs = new Vector(); //collections of the publisher 1 collectionVOs.add(collection1VO);collectionVOs.add(collection2VO); publisher1VO.setCollectionVOs(collectionVOs); PublisherVO publisher2VO = new PublisherVO(); // publisher 2 of the group 30 publisher2VO.setIdPublisher(new Integer(2)); publisher1VO.setIdGroup(new Integer(30)); publisher2VO.setName(" name"); publisher2VO.setDescription("publisher 2 of the group 30"); CollectionVO collection1VO = new CollectionVO(); collection1VO.setIdCollection(new Integer(1));collection1VO.setIdPublisher(new Integer(2)); collection1VO.setIdGroup(new Integer(30)); collection1VO.setDescription("collection 1 of the publisher 2 of the group 30"); BookVO book1VO = new BookVO(); // book 1 of the collection 1 of the publisher w of the group 30 book1VO.setIdBook(new Integer(1)); book1VO.setIdCollection(new Integer(1)); book1VO.setIdPublisher(new Integer(2)); book1VO.setIdGroup(new Integer(30)); Vector authorVOs = new Vector(); // authors of the book 1 of the collection 1 of the publisher 2 of the group 30 AuthorVO authorVO = new AuthorVO(); authorVO.setIdAuthor(new Integer(109));authorVO.setFullname("some name"); authorVOs.add(authorVO); authorVO = new AuthorVO();authorVO.setIdAuthor(new Integer(110)); authorVO.setFullname("some other name");authorVOs.add(authorVO); book1VO.setAuthorVOs(authorVOs); BookVO book2VO = new BookVO();// book 2 of the collection 1 of the publisher 2 of the group 30 book2VO.setIdBook(new Integer(2)); book2VO.setIdCollection(new Integer(1)); book2VO.setIdPublisher(new Integer(2)); book2VO.setIdGroup(new Integer(30)); authorVOs = new Vector(); //authors of the book 2 of the collection 1 of the publisher 2 of the group 30 authorVO = new AuthorVO();authorVO.setIdAuthor(new Integer(111));authorVO.setFullname("some name"); authorVOs.add(authorVO); authorVO = new AuthorVO();authorVO.setIdAuthor(new Integer(112)); authorVO.setFullname("some other name");authorVOs.add(authorVO); book2VO.setAuthorVOs(authorVOs); Collection bookVOs = new Vector(); // books of the collection 1 of the the publisher 2 of the group 30 bookVOs.add(book1VO);bookVOs.add(book2VO); collection1VO.setBookVOs(bookVOs); CollectionVO collection2VO = new CollectionVO(); collection2VO.setIdCollection(new Integer(2));collection2VO.setIdPublisher(new Integer(2)); collection2VO.setIdGroup(new Integer(30)); collection2VO.setDescription("collection 2 of the publisher 2 of the group 30"); book1VO = new BookVO(); //book 1 of the collection 2 of the publisher 2 of the group 30 book1VO.setIdBook(new Integer(1)); book1VO.setIdCollection(new Integer(2)); book1VO.setIdPublisher(new Integer(2)); book1VO.setIdGroup(new Integer(30)); authorVOs = new Vector(); // authors of the book 1 of the collection 2 of the publisher 2 of the group 30 AuthorVO authorVO = new AuthorVO(); authorVO.setIdAuthor(new Integer(113));authorVO.setFullname("some name"); authorVOs.add(authorVO); authorVO = new AuthorVO();authorVO.setIdAuthor(new Integer(114)); authorVO.setFullname("some other name");authorVOs.add(authorVO); book1VO.setAuthorVOs(authorVOs); BookVO book2VO = new BookVO(); //book 2 of the collection 2 of the publisher 2 of the group 30 book2VO.setIdBook(new Integer(2)); book2VO.setIdCollection(new Integer(2)); book2VO.setIdPublisher(new Integer(2)); book2VO.setIdGroup(new Integer(30)); authorVOs = new Vector(); //authors of the book 2 of the collection 2 of the publisher 2 of the group 30 authorVO = new AuthorVO();authorVO.setIdAuthor(new Integer(115));authorVO.setFullname("some name"); authorVOs.add(authorVO); authorVO = new AuthorVO();authorVO.setIdAuthor(new Integer(116)); authorVO.setFullname("some other name");authorVOs.add(authorVO); book2VO.setAuthorVOs(authorVOs); bookVOs = new Vector(); // books of the collection 2 of the the publisher 2 of the group 30 bookVOs.add(book1VO);bookVOs.add(book2VO); collection2VO.setBookVOs(bookVOs); Vector collectionVOs = new Vector(); //collections of the publisher 2 collectionVOs.add(collection1VO);collectionVOs.add(collection2VO); publisher2VO.setCollectionVOs(collectionVOs); Vector publisherVOs = new Vector(); // publishers of the group 30 publisherVOs.add(publisher1VO); publisherVOs.add(publisher2VO); groupVO.setPublisherVOs(publisherVOs); try { BD bd = ServiceLocator.getInstance().getManagerBD("BDFactoryDefaultClass","DefaultBDFactory.BDClass"); groupVO = (GroupVO) bd.insert(groupVO); // groupVO hold the same inserted object } catch (ApplicationException e) { //manage the exception } |
As you can see in the above example you can build a very structured object hold by a main object(here groupVO) and then insert it just with a line of code:'bd.insert(groupVO)'. With just this line of code will be inserted all his publisher collection and so on. That's thanks to ojb, the persistence engine used in the implementention of the DAO (Data Access Object). Mandragora just hide the transaction and connection management. Anyway to use a so powerful insert instruction, you have to take care about the mapping configuration, (for Ojb the repository.xml). In this example you have to take care about circular references, that exists in the diagram. Anyway that the reference exists in the class diagram doesn't mean that it exists in the mapping configuration. If you have circular reference for each publisherVO you must set his attribute groupVO with the correspondent instance of GroupVO, for each collectionVO you must set his attribute publisherVO with the correspondent instance of PublisherVO, and so on. If a circular reference you have set the autoupdate in both side you get in a loop (for example you have the mapping configurated so that when you insert or update a publisher it inserts or updates his group too, and so that when you insert or update the group it inserts or updates his publishers). So take care to map properly.
To what may concern authors and books, if the configuration mapping is set so that when you insert a book it automatically insert or update his authors, as we already told some of the authors we want to insert could already exist in the database, as the relationship between author and book is M:N. If an author (his idAuthor) doesn't exist will be inserted, and if it already exists will be updated with the attributes of the value object; in both cases (an author be inserted or updated) will be inserted a row in the corresponding table holding the M:N relationship.
The method is : update(Object updateVO)
It updates the object updateVO in the underlying datastore. The operation is atomic. Connection management and transaction management are fully delegated. User must not care at all!!. For example suppose you want to modify the book identified by the primary key (23,21,45,4). You have to find it by his primary key in the datastore, load it in some value object, make the modification you need, and then store it again.
| try { BD bd = ServiceLocator.getInstance().getManagerBD("BDFactoryDefaultClass","DefaultBDFactory.BDClass"); BookVO bookVO = (BookVO)bd.findByPrimaryKey(BookVO.class, new Object[]new Integer(23),new Integer(21),new Integer(45),new Integer(4)); // do your job bookVO = bd.update(bookVO); // bookVO hold the same updated object } catch (ApplicationException e) { //manage the exception } |
Of course when you apply the findByPrimaryKey method it could be that bookVO's reference attributes (authorVOs and collectionVO) be populated, depending by the configuration mapping (for ojb look at http://db.apache.org/ojb/docu/guides/basic-technique.html) so that bookVO could be the main object of a complex structure. When then you apply the method update to a value object it could have effect not just on the table mapped to BookVO class, but on tables mapped to related classes too depending always by the mapping configuration. Once you have the bookVO, if his reference attributes (authorVOs and collectionVO) are not populated, you can use the retriever methods, or you can use the setter methods. So, as told you can have a complex structure, and you can modify it as you want, and then with just the line 'bd.update(bookVO)' store it in one atomic transaction, with the proper configuration of the mapping.
Let's see some examples: in the above examples we supposed that the key for BookVO was 'idBook,idCollection,idPublisher,idGroup', the key of CollectionVO was 'idCollection,idPublisher,idGroup', and they key of PublisherVO was 'idPublisher,idGroup'. We suppose now that the key of BookVO is just idBook, the key of CollectionVO is just 'idCollection' and the key of PublisherVO is just 'idPublisher'. We want to get from the database the book identified by the primary key (23), with his collection, publisher and group, but the mapping is configured so that they are not retrieved automatically. We know that this book belongs to the collection 21 but we want to modify it so that it belong to the collection 34 and no more to the collection 21. And in the collection 34 we want to change his description. The mapping is configured so that updating the book, will be updated the collection, updating the collection will be updated the publisher, and with it the group.
| try { BD bd = ServiceLocator.getInstance().getManagerBD("BDFactoryDefaultClass","DefaultBDFactory.BDClass"); BookVO bookVO = (BookVO)bd.findByPrimaryKey(BookVO.class, new Integer(23)); CollectionVO collectionVO = (CollectionVO)bd.findByPrimaryKey(CollectionVO.class, new Integer(34)); bd.retrievePathReference(collectionVO, "publisherVO.groupVO" ); collectionVO.setDescription(collectionVO); bookVO.setCollectionVO(collectionVO) bookVO = bd.update(bookVO); // bookVO hold the same updated object } catch (ApplicationException e) { //manage the exception } |
Suppose now that the same publisher that holds the the book with idBook 23 in the collection 25, decides to create a new collection and hols the book 23 inside it. You could do so:
| try { BD bd = ServiceLocator.getInstance().getManagerBD("BDFactoryDefaultClass","DefaultBDFactory.BDClass"); BookVO bookVO = (BookVO)bd.findByPrimaryKey(BookVO.class, new Integer(23)); PublisherVO publisherVO = (PublisherVO)bd.findByPrimaryKey(PublisherVO.class, bookVO.getPublisherVO()); bd.retrieveReference(publisherVO, "groupVO"); CollectionVO collectionVO = new CollectionVO(); collectionVO.setIdCollection(new Integer(1000)); collectionVO.setIdPublisher(publisherVO.getIdPublisher()); collectionVO.setIdGroup(publisherVO.getIdGroup()); collectionVO.setPublisherVO(publisherVO); bookVO.setIdCollection(new Integer(1000)); bookVO.setCollectionVO(collectionVO); bookVO = bd.update(bookVO); // bookVO hold the same updated object } catch (ApplicationException e) { //manage the exception } |
In the above example, supposing the autoupdate configuration in the chain, 'bookVO.collectionVO.publisherVO.groupVO', with the line 'bd.update(bookVO)' will be updated the field idCollection in the table of the books, will be inserted a new collection in the table of the collection, that will be referenced with the same publisher of the book.
Let's see now how update works when the main object has attributes that are collections of value objects. Suppose now, that the mapping is configured so that updating the group, publishers referenced be update automatically. Suppose we want to modify the description of the group number 30, modify the description of one of his publishers, concretely the number 12, and add one publisher to his ones.
| import it.aco.mandragora.common.Utils; ...... try { BD bd = ServiceLocator.getInstance().getManagerBD("BDFactoryDefaultClass","DefaultBDFactory.BDClass"); GroupVO groupVO = (GroupVO)bd.findByPrimaryKey(GroupVO.class, new Integer(30)); groupVO.setDescription("some description"); bd.retrieveReference(groupVO, "publisherVOs"); PublisherVO number12PublisherVO = (PublisherVO)Utils.selectWhereFieldEqualsTo(groupVO.getPublisherVOs, "idPublisher", new Integer(12)); number12PublisherVO.setDescription("some description");; PublisherVO publisherVO = new PublisherVO(); publisherVO.setIdPublisher(new Integer(199)); publisherVO.setIdGroup(new Integer(30)); publisherVO.setName("name"); publisherVO.setDescrption(" description "); groupVO.getPublisherVOs.add(publisherVO); groupVO = bd.update(groupVO); // groupVO hold the same updated object } catch (ApplicationException e) { //manage the exception } |
Note in the above example the use of 'Utils.selectWhereFieldEqualsTo', that returns an element of a collection that must be a value object, that has an attribute with the name specified by the second input parameter that assumes the value specified by the third one. See Queries on collections. The line of code 'bd.update(groupVO)' update in the row of the group number 30 his description, in the row of the publisher number 12 his description too, and insert the new publisher number 199.
Note that if in the collection 'groupVO.getPublisherVOs' you remove some elements before the update, it won't be deleted from the database. So if you do :
| try { BD bd = ServiceLocator.getInstance().getManagerBD("BDFactoryDefaultClass","DefaultBDFactory.BDClass"); GroupVO groupVO = (GroupVO)bd.findByPrimaryKey(GroupVO.class, new Integer(30)); groupVO.getPublisherVOs.clear(); groupVO = bd.update(groupVO); } catch (ApplicationException e) { //manage the exception } |
publishers won't be deleted. They still are in the database. The method update never delete. If you want do something like that you should use updateCollectionReference, updateCollectionReferences, updateCreateTrees
The method is : updateCollection(Collection updateVOs)
This method updates all objects in the collection updateVOs in an atomic transaction, without user have to carry about connection and transaction management. The collection must be of value objects, and for each of them will this method will act as update or insert depending by if the value object already exists or not in the datastore. The value object of the collection must not necessarily be instance of the same class.
The method is : updateCollectionReference(Object storeVO, String pAttributeName)
This method updates the object storeVO in the same way of update, and delete all objects of the collection associated to pAttributeName. pAttributeName has to be the name of a collection properties. In other words it deletes all objects in the datastore not present in the collection specified by pAttributeName. So if the main object storeVO has a reference collection named pAttributeName configured with an autoupdate, with this method you update the same main object, update all value object of the collection storeVO.pAttributeName, insert all element of this collection not existing in the database, and delete referenced rows in the database the are not in the collection. Connection management and transaction management are fully delegated. User must no care at all as always.
Referring to the diagram at the beginning, suppose that the mapping is configured so that updating the group, publishers referenced be update automatically. Suppose we want to modify the description of the group number 30, modify the description of one of his publishers, concretely the number 12, remove an other publisher,concretely the number 15, and add one publisher to his ones.
| import it.aco.mandragora.common.Utils; ...... try { BD bd = ServiceLocator.getInstance().getManagerBD("BDFactoryDefaultClass","DefaultBDFactory.BDClass"); GroupVO groupVO = (GroupVO)bd.findByPrimaryKey(GroupVO.class, new Integer(30)); groupVO.setDescription("some description"); bd.retrieveReference(groupVO, "publisherVOs"); PublisherVO number12PublisherVO = (PublisherVO)Utils.selectWhereFieldEqualsTo(groupVO.getPublisherVOs, "idPublisher", new Integer(12)); number12PublisherVO.setDescription("some description");; PublisherVO publisherVO = new PublisherVO(); publisherVO.setIdPublisher(new Integer(199)); publisherVO.setIdGroup(new Integer(30)); publisherVO.setName("name"); publisherVO.setDescrption(" description "); groupVO.getPublisherVOs.add(publisherVO); Iterator iterator = groupVO.getPublisherVOs.iterator(); publisherVO = new PublisherVO(); while iterator.hasNext(){ publisherVO = (PublisherVO)iterator.next(); if (publisherVO.getIdPublisher().intValue()==15) { iterator.remove(); break; } } groupVO = bd.updateCollectionReference(groupVO,"publisherVOs"); // groupVO hold the same updated object } catch (ApplicationException e) { //manage the exception } |
Note in the above example the use of 'Utils.selectWhereFieldEqualsTo', that returns an element of a collection that must be a value object, that has an attribute with the name specified by the second input parameter that assumes the value specified by the third one. See Queries on collections. The line of code 'bd.updateCollectionReference(groupVO,"publisherVOs")' update in the row of the group number 30 his description, in the row of the publisher number 12 his description too, and insert the new publisher number 199, and delete the the row of the publisher number 15.
The method is : updateCollectionReferences(Object storeVO)
This method acts as updateCollectionReference with the difference that it acts on all collection references./br Connection management and transaction management are fully delegated. User must no care at all as always.
Mandragora has one methods storePathsCascade:
This method has the same behavior of
where the collection paths has just one element that is the input parameter path, and where pathsHasToBeSorted and storeVOHasToBeStored are both true
Mandragora has one methods storePathsCascade:
This method creates or updates the value objects on a tree performing insert and update operations. The tree is represented by storeVO, that is the value object root, and paths, that is a collection of strings that are the paths of the tree from the root Each element of paths is a dot separated list of attributes; for example it could be:
attribute_1.attribute_2.attribute_3.attribute_4
We will deal with storeVO as attribute_0. The nodes of level i of the tree are all labeled attribute_i. The generic attribute_i can represent a value object or a collection. The attribute_i must be a property of attribute_i-1 if attribute_i-1 is a value object, and must be a property of each element ofattribute_i-1 if attribute_i-1 is a collection. So storeVO must have a property named attribute_1 that can be a value object or a collection; the value object or each element of the collection must have a property named attribute_2 that can be a value object or a collection too. And so on. Nodes of level i in the tree will be value objects that are the property named attribute_i or all elements (that are value objects too) of collections that are the property named attribute_i.
When called this method apply the following algorithm:
| for each elements of trees: 1- Object storeVO will be updated if storeVO exists. If not it will be created. 2- For each elements of paths: 2.1- Each node of level i will be created or updated, and it will be related to its father: \concretely if the elements of the current level belong to a collection they will be linked to the father, \while if are a simple valueobject, its father will be linked to it. |
Suppose you have a class diagram representing the structure of your value object like the following:
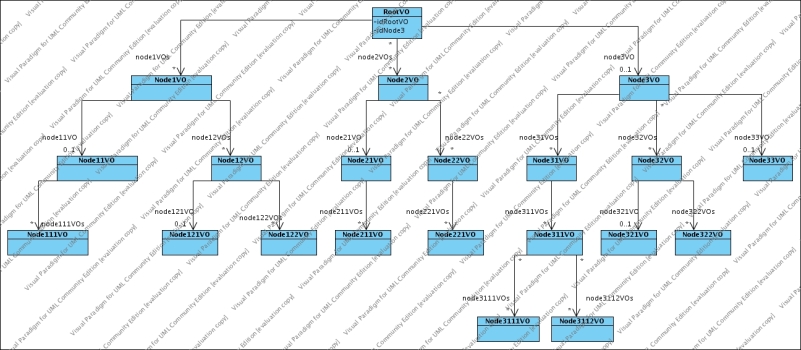
and that you have a value object as represented by the following object diagram:

To store all this structure you have just to do:
| String path1 = "node1VOs.node11VO.node111VOs"; String path2 = "node1VOs.node12VOs.node121VO"; String path3 = "node1VOs.node12VOs.node122VOs"; String path4 = "node2VOs.node21VO.node211VOs"; String path5 = "node2VOs.node22VOs.node221VOs"; String path6 = "node3VO.node31VOs.node311VOs.node3111VOs"; String path7 = "node3VO.node31VOs.node311VOs.node3112VOs"; String path8 = "node3VO.node32VOs.node321VO"; String path9 = "node3VO.node32VOs.node322VOs"; String path10 = "node3VO.node33VO"; ArrayListString paths = new ArrayListString(); paths.add(path1); paths.add(path2); paths.add(path3); paths.add(path4); paths.add(path5); paths.add(path6); paths.add(path7); paths.add(path8); paths.add(path9); paths.add(path10); try { BD bd = ServiceLocator.getInstance().getManagerBD("BDFactoryDefaultClass","DefaultBDFactory.BDClass"); bd.storePathsCascade(cRootVO,paths, Boolean.TRUE, Boolean.TRUE); } catch (ApplicationException e) { //manage the exception } |
Note that existing object are updated, while new ones are inserted, and in both cases, the right relationship are stored as well, even if not specified by the value objects attributes representing such relationships.
The collection of paths must be ordered to make the method work, anyway, of it is not , specifying the input parameter pathsHasToBeSorted true, the method will order it for you.
The parameter storeVOHasToBeUpdated states if, in the case that rootVO already exists in the database, rootVO must be updated in the database or not.
Mandragora has three methods updateCreateTrees:
These methods create or update a collection of trees in the underlying media store, performing delete, insert, and update operations. All trees have a common root that is rootVO, that can be considered the main object. The collection of trees is represented by the input parameter trees that is a collection of String. Each element of the collection trees is a dot separated list of attributes; for example one of the element of the collection could be: "attribute_1.attribute_2.attribute_3.attribute_4" that represent a tree with as root the main object rootVO that we may consider as attribute_0. The nodes of level i of a tree represented by the string "attribute_1.attribute_2. .. .attribute_i. ... .attribute_n" are all labeled attribute_i. The generic attribute_i can represent a value object or a collection, and the attribute_i must be an attribute of attribute_i-1. if attribute_i-1 is a value object, and must be an attribute of each element ofattribute_i-1 if attribute_i-1 is a collection. So rootVO must have an attribute named attribute_1 that can be a value object or a collection; the value object or each element of the collection must have an attribute named attribute_2 that can be a value object or a collection too. And so on. Nodes of level i in the tree will be value objects that are the attribute named attribute_i or all elements (that are value objects too) of collections that are the attribute named attribute_i.
The differences between the signatures are the boolean parameters storeVOHasToBeUpdated, deleteChangedOneToOne, applyDeletePathCascade, ifM2NDeleteOnlyRelationship, deleteOneToOne.
The parameter storeVOHasToBeUpdated states if, in the case that rootVO already exists in the database, rootVO must be updated in the database or not. The default is true, so executing the first of the two signatures is equivalent to execute the second one with parameter storeVOHasToBeUpdated equal to true.
The parameter deleteChangedOneToOne specifies if in 1 to 1 relationships, if the child is changed with respect to the media store relationship, the element in the media store has to be deleted or not. If not specified is assumed to be false.
The parameter applyDeletePathCascade specifies if an object to delete across the codetrees/code have to be deleted with cascade on the remaining codetrees/code, or have to be just a simple delete. If not specified is assumed to be true.
The parameter ifM2NDeleteOnlyRelationship specifies if when an object have to be deleted and has a M2N relationship with its father on the codepath/code, the object have to be deleted or just its relationship with the father. If not specified is assumed to be true.
The parameter deleteOneToOne specifies if applying the delete cascade, when found a 1 to 1 relationship, the cascade must still be applied or not. If not specified is assumed to be false.
An example of tree, referring to the class diagram at the beginning could be the following that have some intance of GroupVO as root
| "publisherVOs.collectionVOs.bookVOs" |
The tree represented could be for example:

In this example attributes are always collections. It is not hard imaging some simple value object inside.
Let's see now how this method works on the depicted structure. When called this method apply the following algorithm:
| 1 - Object rootVO will be updated if it exists and the input update parameter storeVOHasToBeUpdated is true. If it doesn't exist will be created 2 - For each elements of trees 2.1 - Each node of level i will be created or updated. 2.2 - For each node of level i which attribute_i+1 is a collection, it will look in the underlying media store for all objects represented by attribute_i+1 related to the node of level i being processed and not present between its children: If the collection is 1 to N or it is M to N and the parameter ifM2NDeleteOnlyRelationship is false, the found objects will be deleted from the media store, while if it is M to N with ifM2NDeleteOnlyRelationship true, only the relationship between such object and its father will be deleted from the media store. When an object is deleted, it can be applied a delete cascade until the bottom of the tree being processed or it can be a simple delete, depending on the input parameter applyDeletePathCascade. In the case of applyDeletePathCascade true, the cascade will stop in the bottom of the tree being processed, or when deleting is found a 1 to 1 relationship and the input parameter deleteOneToOne is false or is found an M to N relationship and ifM2NDeleteOnlyRelationship , in which case the relationship is deleted, and deletion stopped. 2.3 - For each node of level i which attribute_i+1 is a simple value object, if deleteChangedOneToOne is true, this method will check if such value object is different from the correspondent stored in the media store, and if so the element in the media store will be deleted. If the value object of attribute_i+1 is null and the correspondent in the media store is not, they will be considered distinct. If a deletion is applied, the same rules of the case of the collection is applied, so the parameters applyDeletePathCascade, ifM2NDeleteOnlyRelationship and deleteOneToOne will be considered. |
Suppose that we have an instance groupVO of the class GroupVO, as depicted in the above picture, applying the following code:
| String tree = "publisherVOs.collectionVOs.bookVOs"; Vector trees = new Vector(); trees.add(tree); try { BD bd = ServiceLocator.getInstance().getManagerBD("BDFactoryDefaultClass","DefaultBDFactory.BDClass"); groupVO = (GroupVO)bd.updateCreateTrees(groupVO, trees); } catch (ApplicationException e) { //manage the exception } |
the database will reflect exactly the data in the picture. So if in the database existed a publisher number 3, referred to our group, it will be deleted , while if the publisher number 2 didn't exist it will be created, and if it existed will be updated, an following deep in the tree, the same for all levels.
The method is : delete(Object deleteVO)
This methods deletes the object deleteVO from the underlying datastore. The operation is atomic. Connection management and transaction management are fully delegated and user must no care at all!
For example if you want to delete the group number 20 just do:
| GroupVO groupVO = new GroupVO groupVO.setIdGroup(new Integer(20)); try { BD bd = ServiceLocator.getInstance().getManagerBD("BDFactoryDefaultClass","DefaultBDFactory.BDClass"); bd.delete(groupVO); } catch (ApplicationException e) { //manage the exception } |
The method is : deleteCollection(Collection deleteVOs)
This methods deletes all the objects of the collection deleteVOs from the underlying datastore. The operation is atomic. Connection management and transaction management are fully delegated and user must no care at all!
Suppose you want to delete some users paolo, marco, and aldo from your database in an atomic transaction, you have just to do:
| Collection<UserVO> toDeletedUserVOs = new ArrayList<UserVO>(); toDeletedUserVOs.add(paoloUserVO); toDeletedUserVOs.add(marcoUserVO); toDeletedUserVOs.add(aldoUserVO); try { BD bd = ServiceLocator.getInstance().getManagerBD("BDFactoryDefaultClass","DefaultBDFactory.BDClass"); bd.deleteCollection(toDeletedUserVOs); } catch (ApplicationException e) { //manage the exception } |
The method is : deleteMToNRelationshipCollection(Object left, String leftFieldName, Collection rightCollection)
This method deletes the M2N relationship between the main object left and all the elements of the collection rightCollection, relationship represented by the attribute leftFieldName of left. This method supposes it exists a M2N relationship in the media store between the objects of the class of left and the objects of the class of the elements of the collection rightCollection. If left or rightCollection are null nothing is done.
Suppose you have a valuobject mainVO of the class MainVO, that is related in the media store through a M2N relationship, to many objects of the class ReferenceVO and we want to delete such relation to two of such objects, that we call aReferenceVO and bReferenceVO. We suppose that the class MainVO has an attribute referenceVOs that is a collcetion of instances of ReferenceVO. We have just to do :
| Collection<ReferenceVO> referenceVOs = new ArrayList<ReferenceVO>(); referenceVOs.add(aReferenceVO); referenceVOs.add(bReferenceVO); try { BD bd = ServiceLocator.getInstance().getManagerBD("BDFactoryDefaultClass","DefaultBDFactory.BDClass"); bd.deleteMToNRelationshipCollection(mainVO,"referenceVOs",referenceVOs); } catch (ApplicationException e) { //manage the exception } |
Just the relationship between the involved objects is deleted, while the objects aReferenceVO and bReferenceVO are no touched at all.
Mandragora has three methods deleteItemsNotInCollectionsInPath:
These methods delete from the underlying media store the items that are not in the collections in the path represented by the input parameter path, and starting from rootVO, where path is a dot separated list of attributes, each one being a value object or a collection of value objects. Starting from the root, if the first attribute of path is a 1 to 1 relationship, if the value of such attribute is null this method ends, otherwise, it carries on recursively using the value of first attribute as the new rootVO and the remaining path as the new path. If the first attribute of path is a collection of the rootVO and it is a 1 TO N or a M TO N relationship with ifM2NDeleteOnlyRelationship == false, this method deletes all the items in the database linked to the item relative to rootVO and that are not present in the collection of the first attribute value. If ifM2NDeleteOnlyRelationship == true only their relationship will be deleted. Depending on the value of the input parameter applyDeletePathCascade, the items will be deleted applying a delete cascade on all the remaining path, in such case if the input parameter deleteOneToOne is true the cascade delete will be applied to the 1 TO 1 relationship as well, otherwise the cascade delete will stop at the first 1 TO 1 relationship found. Whatever will be the value of the input parameter applyDeletePathCascade, if the input parameter ifM2NDeleteOnlyRelationship is true, when a M2N relationship is found only the relationship of the M2N relationship table will be deleted, and the corresponding object  won't be touched in the database. Note that such condition, in the applyDeletePathCascade case, will cause the delete cascade to stop when a M2N relationship is found. Note that the parameter deleteOneToOne will cause just the deletion of ONE TO ONE related objects only of the children of nodes that have been decided to be deleted because not held by some collection, and such parameter don't  force the deletion of ONE TO ONE related objects in the database that are null or have changed on the path. So the deleteOneToOne parameter have sense just in the applyDeletePathCascade ==true case. Finally this method carries on recursively for each one of the children of rootVO held by the first attribute value treated as new rootVO, and with the remaining path as new path. If rootVO is null or path is null or empty or blank character string, nothing is done.
Suppose to have a value object structure like the following:

and that the following object diagram represents objects stored in the media store
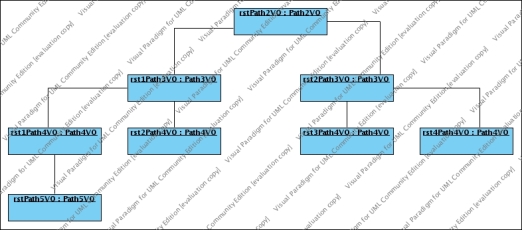
If we load such structure, and then we delete from this structure some objects held by some collection, and we apply one method deleteItemsNotInCollectionsInPath the objects deleted in the structure will be deleted in the media store as well, or, it can be that just the relationship are removed.
For example if we remove rst1Path3VO from the collection of Path3VO held by rstPath2VO, and we remove rst3Path4VO from the collection of Path4VO held by rst2Path3VO, applying the method they will be removed from the media store, and there are other effects, depending on which method is applied, and with with which parameters values. If it is applied:
| deleteItemsNotInCollectionsInPath(rstPath2VO, "path3VOs.path4VOs.path5VO", Boolean.TRUE, Boolean.FALSE, Boolean.TRUE) |
In the media store will be deleted the objects correspondent to rst1Path3VO, rst1Path4VO,rst2Path4VO , rstPath5VO, and rst3Path4VO. Note that rst1Path4VO,rst2Path4VO , rstPath5VO are removed from the media store as cosequence of applyDeletePathCascade==TRUE, and rstPath5VO as consequence of deleteOneToOne==TRUE
If we put it is applied the following ifM2NDeleteOnlyRelationship==True, applying so
| deleteItemsNotInCollectionsInPath(rstPath2VO, "path3VOs.path4VOs.path5VO", Boolean.TRUE, Boolean.TRUE, Boolean.TRUE) |
In the M to N relationships the referenced objects are not deleted, but just their relationship with the main object. So rst1Path3VO, rst1Path4VO,rst2Path4VO , rstPath5VO, and rst3Path4VO won't be deleted, but just the relationship entry between rstPath2VO and rst1Path3VO, and the relationship entry between rst2Path3VO and rst3Path4VO. Even if there is applyDeletePathCascade==TRUE no more objects are deleted because rst1Path3VO is not deleted.
In the case of deleteOneToOne==FALSE :
| deleteItemsNotInCollectionsInPath(rstPath2VO, "path3VOs.path4VOs.path5VO", Boolean.TRUE, Boolean.FALSE, Boolean.FALSE) |
in the media store will be deleted the objects correspondent to rst1Path3VO, rst1Path4VO,rst2Path4VO , and rst3Path4VO but not rstPath5VO.
Using the method
| deleteItemsNotInCollectionsInPath(Object rootVO, String path) |
is the same of
| deleteItemsNotInCollectionsInPath(Object rootVO, String path, Boolean.TRUE, Boolean.TRUE, Boolean.FALSE) |
and using the method
| deleteItemsNotInCollectionsInPath(Object rootVO, String path,Boolean ifM2NDeleteOnlyRelationship, Boolean deleteOneToOne) |
is the same of
| deleteItemsNotInCollectionsInPath(Object rootVO, String path, Boolean ifM2NDeleteOnlyRelationship, Boolean.TRUE, Boolean.FALSE) |
The method is : deleteItemsNotInCollectionsInPaths(Object rootVO, Collection paths, Boolean applyDeletePathCascade, Boolean ifM2NDeleteOnlyRelationship, Boolean deleteOneToOne)
This method has the same behavior of
but is applied to all paths that are in the collection paths.
The method is : deletePathCascade(Object parentVO,String path,Boolean ifM2NDeleteOnlyRelationship, Boolean deleteOneToOne)
This method deletes the main object parentVO and applies a delete cascade on all the elements related trough the relationship along the path. The delete cascade stops at the end of the path or when it finds a 1 to 1 relationship and deleteOneToOne is false, or when it finds a M2N relationship and ifM2NDeleteOnlyRelationship is true. If parentVO is null nothing is done.
Suppose we still have the object rstPath2VO as the figure, that represents what is stored as well. If we apply the method
| deletePathCascade(rstPath2VO, "path3VOs.path4VOs.path5VO", Boolean.FALSE, Boolean.TRUE) |
all the structure will be deleted in the media store.
If we apply the same method with deleteOneToOne=FALSE
| deletePathCascade(rstPath2VO, "path3VOs.path4VOs.path5VO", Boolean.FALSE, Boolean.FALSE) |
all the structure will be deleted in the media store except rstPath5VO. And if ifM2NDeleteOnlyRelationship=TRUE
| deletePathCascade(rstPath2VO, "path3VOs.path4VOs.path5VO", Boolean.TRUE, Boolean.FALSE) |
only rstPath2VO will be deleted with the M2N relationship between rstPath2VO and rst1Path3VO, and between rstPath2VO and rst2Path3VO, and rst1Path3VO and rst2Path3VO won't be deleted nor the objects down them.
The method is : deletePathsCascade(Object parentVO, Collection paths,Boolean ifM2NDeleteOnlyRelationship, Boolean deleteOneToOne)
This method has the same behavior of deletePathCascade, but it is applied to all paths that are in the collection paths. If parentVO is null nothing is done.
There are three kind of business methods to manage maps:
These methods manage the relationship betweem maps and collections
Mandragora has three methods buildMap:
These methods create a new Map using the values of specific attributes of the elements of a collection of value objects provided by input parameters. Such collection can be specified by the two inputs parameters pInstance and pAttributeName, where pInstance is the bean holding the collection to be used and pAttributeName is the name of the attribute of pInstance that represents the collection. So definitively the collection to be used is pInstance.pAttributeName. The collection can be specified too, by the single parameter valueObjectsCollection.
In the case the collection is specified by pInstance.pAttributeName and it is null, it will be retrieved from the media store (see retrieveReference), and if it is still null an empty map will be returned. In the case the collection is specified by valueObjectsCollection and it is null an empty map will be returned as well.
If the collection is not null, if isValueObjectKeyAttributeNameToSet is not null and true, it will be executed the setter method with no arguments on the attribute whose name is represented by the input string valueObjectKeyAttributeName for each element of the collection. So for example, if valueObjectKeyAttributeName == "name", the method setName() will be executed on each element of the collection. (Of course each of such elements must provide that method). Every value object of the collection must have an attribute named as specified by the input string parameter valueObjectKeyAttributeName, with its setter and getter.
If the collection is not null, for each value object of the collection it will be got the value of the attribute specified by valueObjectKeyAttributeName (ie. getName()), and if this value is not null a new entry for the map will be created and its key will be the gotten value of the attribute valueObjectKeyAttributeName (ie. getName()); so it will be created an entry in the map for each element of the collection for which the attribute specified by the input parameter valueObjectKeyAttributeName has not null value. The entry's key will be the value of the same attribute specified by the input parameter valueObjectKeyAttributeName. The entry's value depends by if the input parameter mapValueClass is null or not null.
If mapValueClass is null the entry's value will be the value of the attribute specified by the input parameter valueObjectValueAttributeName.
For example suppose that valueObjectKeyAttributeName == "name" and valueObjectValueAttributeName == "age", for each element of the collection which has element.getName() != null on the created map that will be returned will be done
If the String valueObjectValueAttributeName is null or empty string or blank characters string it will be forced to assume the value of valueObjectKeyAttributeName,that, can't be null, nor empt nor blanck chacters string to not be thrown a ApplicationException. In other words this method will create a map and will do:
for each element of the collection for which element.valueObjectKeyAttributeName is not null.
If the input parameter mapValueClass is not null a new instance of mapValueClass will be created, with the no arguments constructor, and it will be used as value of the entry being processed of the map to be returned.
As in the previous case, from the element of the collection of value objects that is being processed, it will be gotten the value of the attribute specified by valueObjectValueAttributeName and if not null, it will used to set in the mapValueClass class the attribute specified by the input parameter mapValueClassAttributeToSetName.
For example suppose that mapValueClass==Age.class, and mapValueClassAttributeToSetName == "yearsOld", the entry value relative to the value object that is being processed will be new Age(), and if element.getAge() is not null, on the Age instance will be applied setYearsOld(element.getAge())
Of course the mapValueClass must have available the no arguments constructor; the attribute specified by valueObjectValueAttributeName must exist in the elements of the collection, and the attribute specified by mapValueClassAttributeToSetName must exist in the mapValueClass class. If the input string parameter mapValueClassAttributeToSetName is null, or empty string, or blank character string, it will be forced to assume the value of valueObjectValueAttributeName, that in turn, in the same condition is forced to assume the value of valueObjectKeyAttributeName.
Finally the newly created instance of mapValueClass will be used as entry's value of the map, doing: